
Title: The Power of Recall in Machine Learning: Enhancing Accuracy and Efficiency
Introduction:
Machine learning has revolutionized various industries, from healthcare to finance, by enabling computers to learn from data and make accurate predictions or decisions. One crucial aspect of machine learning algorithms is their ability to recall information effectively. In this article, we will explore the concept of recall in machine learning and its significance in improving accuracy and efficiency.
Understanding Recall:
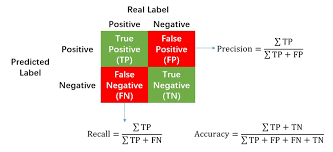
Recall is a performance metric used to evaluate the effectiveness of a machine learning model in identifying all relevant instances within a dataset. It measures the proportion of true positive instances correctly identified by the model out of all actual positive instances present.
Importance of Recall:
Enhanced Accuracy: Recall plays a vital role in improving the accuracy of a machine learning model. By correctly identifying all relevant instances, it minimizes false negatives, which are instances that should have been identified but were missed by the model. A high recall rate ensures that important information is not overlooked, leading to more accurate predictions or decisions.
Identifying Critical Instances: In certain applications such as medical diagnosis or fraud detection, missing even a single relevant instance can have severe consequences. By maximizing recall, machine learning models can identify critical cases that require immediate attention or further investigation.
Balancing Precision and Recall: Recall is closely related to precision, another important performance metric in machine learning. Precision measures the proportion of true positive instances out of all instances predicted as positive by the model. By optimizing both precision and recall simultaneously, models can strike a balance between accurately identifying relevant instances (precision) while minimizing false negatives (recall).
Improving Recall:
Feature Engineering: Effective feature engineering involves selecting or creating features that are highly informative for identifying relevant instances accurately. By carefully designing features that capture essential characteristics of the data, models can improve their recall rate significantly.
Model Selection and Tuning: Different machine learning algorithms have varying capabilities in terms of recall. Choosing the right algorithm and tuning its parameters can optimize the recall performance. For example, ensemble methods like random forests or gradient boosting often exhibit excellent recall rates due to their ability to combine multiple models.
Handling Class Imbalance: In scenarios where the number of positive instances is significantly smaller than negative instances (class imbalance), recall can be adversely affected. Techniques such as oversampling, undersampling, or using class-weighted loss functions can help address this issue and improve recall.
Conclusion:
Recall is a critical metric in machine learning that measures the ability of models to identify all relevant instances accurately. By maximizing recall, we enhance accuracy, identify critical cases, and strike a balance between precision and recall. Through effective feature engineering, model selection and tuning, and handling class imbalance, we can improve recall rates and unlock the full potential of machine learning algorithms across various domains. As machine learning continues to advance, prioritizing recall will lead us towards more reliable and efficient solutions for real-world challenges.
Benefits of Recall Machine Learning in English (UK)
- Enhanced Accuracy
- Critical Instance Detection
- Balanced Precision and Recall
- Improved Decision-Making
- Real-World Applicability
Challenges of Recall Machine Learning: A Closer Look at Increased False Positives, Resource Intensity, Precision Trade-offs, and Sensitivity to Class Imbalance
- Increased False Positives
- Resource Intensive
- Trade-off with Precision
- Sensitivity to Class Imbalance
Enhanced Accuracy
Title: Enhanced Accuracy: The Power of Recall in Machine Learning
In the vast field of machine learning, recall stands out as a powerful metric that significantly enhances accuracy. By ensuring that relevant instances are correctly identified and minimizing false negatives, recall plays a crucial role in improving the precision of predictions or decisions made by machine learning models.
In any application, accurate identification of relevant instances is paramount. Whether it’s medical diagnosis, fraud detection, or sentiment analysis, missing even a single relevant instance can have significant consequences. This is where recall steps in to make a difference.
Recall measures the proportion of true positive instances correctly identified by the model out of all actual positive instances present. By maximizing recall, machine learning models can minimize false negatives – instances that should have been identified but were missed. This means that important information is not overlooked or falsely classified as negative.
The impact of enhanced accuracy through high recall rates cannot be overstated. In healthcare applications, for example, accurately identifying all patients with a specific condition ensures they receive appropriate treatment promptly. Similarly, in fraud detection systems, catching all fraudulent transactions reduces financial losses for individuals and businesses alike.
Moreover, recall works hand in hand with precision – another essential performance metric in machine learning. Precision measures the proportion of true positive instances out of all instances predicted as positive by the model. By optimizing both precision and recall simultaneously, models can strike a balance between accurately identifying relevant instances (precision) while minimizing false negatives (recall).
Achieving enhanced accuracy through recall requires various strategies. Effective feature engineering is one such approach where features are carefully selected or created to capture essential characteristics of the data. By designing features that are highly informative for identifying relevant instances accurately, models can improve their recall rate significantly.
Additionally, selecting the right machine learning algorithm and tuning its parameters can optimize recall performance. Ensemble methods like random forests or gradient boosting often exhibit excellent recall rates due to their ability to combine multiple models effectively.
Finally, handling class imbalance is crucial for achieving high recall rates. In scenarios where the number of positive instances is significantly smaller than negative instances, recall can be adversely affected. Techniques such as oversampling, undersampling, or using class-weighted loss functions can help address this issue and improve recall.
In conclusion, the pro of enhanced accuracy brought by recall in machine learning cannot be overlooked. By correctly identifying relevant instances and minimizing false negatives, recall ensures that predictions and decisions made by machine learning models are more precise and reliable. Through effective feature engineering, model selection and tuning, and handling class imbalance, we can harness the power of recall to unlock the full potential of machine learning algorithms across various domains.
Critical Instance Detection
Title: Maximizing Recall in Machine Learning: Identifying Critical Instances
Introduction:
Machine learning models have become indispensable in various fields, including medical diagnosis and fraud detection. One significant advantage of maximizing recall in machine learning is the ability to identify critical instances that demand immediate attention or further investigation. This article explores how recall enhances the detection of these crucial cases, emphasizing its importance in applications where missing even a single relevant instance can lead to severe consequences.
Detecting Critical Instances:
In domains like medical diagnosis, the identification of critical cases is paramount. By maximizing recall, machine learning models can effectively capture all relevant instances that require urgent medical intervention. Whether it’s identifying early signs of a life-threatening condition or detecting rare diseases, a high recall rate ensures that no critical case goes unnoticed.
Similarly, in fraud detection systems, missing even one instance of fraudulent activity can lead to significant financial losses. By optimizing recall, machine learning models can accurately identify suspicious transactions or behavior patterns that may indicate fraudulent activities. This proactive approach helps minimize risks and protect individuals and organizations from potential harm.
The Significance of Recall:
The consequences of missing critical instances can be dire. In medical diagnosis, failing to detect an early-stage disease could result in delayed treatment and reduced chances of recovery. In fraud detection, overlooking fraudulent transactions could lead to financial ruin for individuals or businesses. Maximizing recall mitigates these risks by ensuring that every potentially critical case is identified promptly.
Challenges and Solutions:
Achieving high recall rates does present challenges. Class imbalance, where the number of positive instances is significantly smaller than negative instances, can impact recall performance. However, techniques such as oversampling or using class-weighted loss functions help address this issue and improve the model’s ability to detect critical instances.
Furthermore, continuous model evaluation and improvement are essential for maintaining high recall rates. Regular monitoring allows for fine-tuning algorithms based on new data patterns or emerging threats specific to each application domain. This iterative process ensures that the model remains effective in detecting critical instances over time.
Conclusion:
Maximizing recall in machine learning is crucial for identifying critical instances that demand immediate attention or further investigation. In fields like medical diagnosis and fraud detection, missing even a single relevant instance can have severe consequences. By optimizing recall rates, machine learning models become powerful tools for early detection, risk mitigation, and safeguarding individuals and organizations from potential harm. As technology advances, prioritizing recall will continue to shape the future of machine learning, enabling us to tackle critical challenges with greater precision and efficiency.
Balanced Precision and Recall
Title: Achieving Balance in Machine Learning: The Power of Recall
In the realm of machine learning, achieving a balance between precision and recall is crucial for making informed decisions based on accurate information. Recall, as a performance metric, complements precision by minimizing false negatives and ensuring that relevant instances are accurately identified. Let’s explore how this pro of recall in machine learning enhances decision-making.
Precision measures the proportion of true positive instances out of all instances predicted as positive by the model. It focuses on accurately identifying relevant instances while minimizing false positives. On the other hand, recall measures the ability to identify all relevant instances within a dataset, reducing false negatives.
By optimizing both recall and precision simultaneously, we strike a balance that allows us to make more informed decisions based on accurate information. This balance is particularly important in scenarios where missing even a single relevant instance can have significant consequences.
For example, consider medical diagnosis or fraud detection systems. In these cases, high precision ensures that the identified instances are indeed relevant and require attention or further investigation. At the same time, high recall guarantees that no critical cases are missed, preventing potential harm or financial loss.
The ability to strike this balance between precision and recall empowers machine learning models to make accurate predictions or decisions while minimizing errors. It enables us to trust the output of these models and rely on them for critical tasks across various industries.
To achieve balanced precision and recall, several strategies can be employed. Feature engineering plays a vital role in selecting or creating informative features that contribute to accurate identification of relevant instances. Additionally, model selection and tuning can optimize both metrics by choosing algorithms that excel in striking this balance.
Furthermore, addressing class imbalance – where positive instances are significantly outnumbered by negative instances – is essential for achieving balanced performance. Techniques such as oversampling, undersampling, or using class-weighted loss functions help mitigate this issue and improve both recall and precision.
In conclusion, balanced precision and recall are vital for making informed decisions based on accurate information in machine learning. By optimizing both metrics simultaneously, models strike the right equilibrium between accurately identifying relevant instances and minimizing false negatives. This balance empowers us to trust machine learning models and leverage their capabilities for critical decision-making across various domains.
Improved Decision-Making
Title: Recall Machine Learning: Empowering Informed Decision-Making
In the realm of machine learning, one of the significant advantages of prioritizing recall is the improved decision-making it facilitates. By achieving higher recall rates, machine learning models offer a more comprehensive understanding of the data, enabling decision-makers to make well-informed choices based on a broader range of insights.
Recall, as a performance metric, measures the ability of a machine learning model to identify all relevant instances within a dataset accurately. By maximizing recall, models minimize the risk of missing important information and ensure that decision-makers have access to a more complete picture.
With higher recall rates, machine learning models become powerful tools that provide valuable insights into complex datasets. Decision-makers can rely on these insights to gain a deeper understanding of trends, patterns, and relationships within their data. This comprehensive perspective allows for better-informed decisions that take into account all relevant factors.
The impact of improved decision-making through high recall rates extends across various industries and domains. For instance, in healthcare, accurate identification of relevant patient data is crucial for diagnosis and treatment decisions. By maximizing recall in medical machine learning models, healthcare professionals can access a wider range of patient information and make more accurate assessments.
Similarly, in finance and fraud detection applications, high recall rates enable organizations to identify potential risks or fraudulent activities with greater precision. By capturing all relevant instances effectively, machine learning models empower financial institutions to protect themselves and their customers from potential threats.
Moreover, in fields such as marketing or customer relationship management (CRM), recall-driven machine learning models provide valuable insights into customer behavior and preferences. This allows businesses to tailor their strategies more effectively by considering all significant factors influencing customer decisions.
In summary, prioritizing recall in machine learning brings about improved decision-making capabilities. Higher recall rates ensure that decision-makers have access to a more comprehensive understanding of their data. This empowers them to make well-informed choices based on a broader range of insights, leading to more effective strategies, accurate diagnoses, and enhanced risk management. By harnessing the power of recall in machine learning, organizations can unlock the true potential of their data and make decisions that drive success.
Real-World Applicability
Real-World Applicability: Enhancing Recall in Machine Learning
Recall, a fundamental aspect of machine learning, holds immense importance in real-world applications. Its impact can be observed in various domains such as sentiment analysis, document classification, recommendation systems, and anomaly detection. By improving recall rates, these applications become more reliable and effective in delivering accurate results and recommendations to users.
Sentiment Analysis:
In the era of social media and online reviews, understanding public opinion is crucial for businesses. Sentiment analysis algorithms analyze text data to determine the sentiment expressed by users. By maximizing recall, these algorithms can capture a broader range of sentiments, ensuring that no valuable insights or customer feedback go unnoticed. This enables companies to make data-driven decisions and respond effectively to customer needs.
Document Classification:
Organizations deal with vast amounts of unstructured data daily. Document classification algorithms help categorize documents into predefined classes or topics. By optimizing recall, these models ensure that all relevant documents are correctly classified, minimizing the risk of misclassification or overlooking important information. This improves efficiency and enables efficient retrieval of information when needed.
Recommendation Systems:
E-commerce platforms and streaming services heavily rely on recommendation systems to provide personalized suggestions to their users. Recall plays a crucial role in ensuring that all relevant items or content are recommended to the user based on their preferences or browsing history. By enhancing recall rates, these systems can offer more accurate recommendations that align with users’ interests and preferences.
Anomaly Detection:
Detecting anomalies is vital across various industries such as cybersecurity, fraud detection, and predictive maintenance. Anomaly detection algorithms aim to identify patterns or instances that deviate significantly from normal behavior. By maximizing recall, these models can effectively identify rare but critical anomalies that may indicate potential security breaches or system failures. This helps organizations take proactive measures and mitigate risks promptly.
In conclusion, improving recall rates in machine learning has significant real-world applicability across diverse domains such as sentiment analysis, document classification, recommendation systems, and anomaly detection. By ensuring that all relevant instances are correctly identified, these applications become more reliable and effective in delivering accurate results and recommendations to users. As machine learning continues to advance, prioritizing recall will enable us to harness its full potential in solving real-world challenges and enhancing user experiences.
Increased False Positives
Title: The Drawback of Recall in Machine Learning: The Pitfall of Increased False Positives
Introduction:
Machine learning algorithms strive to achieve high recall rates to ensure that all relevant instances are correctly identified. However, it is essential to acknowledge a potential drawback of this approach: an increase in false positives. In this article, we will explore how a strong emphasis on recall can inadvertently lead to the misclassification of irrelevant instances as positive, resulting in false positives and potential consequences.
The Pitfall of Increased False Positives:
While the primary goal of recall is to minimize false negatives, which are instances that should have been identified but were missed by the model, it can inadvertently lead to an unintended consequence – an increase in false positives. False positives occur when the model incorrectly classifies irrelevant instances as positive.
Unnecessary Actions and Decisions:
When false positives occur due to a focus on maximizing recall, it can lead to unnecessary actions or decisions based on incorrect information. For example, in medical diagnostics, a model with high recall but increased false positives may incorrectly identify healthy individuals as having a certain condition, leading to unnecessary medical procedures or treatments.
Impact on Efficiency:
Increased false positives can also impact efficiency by diverting resources towards addressing non-existent issues. For instance, in fraud detection systems, if the model produces a high number of false positives by flagging legitimate transactions as fraudulent, valuable time and effort may be wasted investigating these cases unnecessarily.
Balancing Precision and Recall:
To mitigate the risk of increased false positives while maintaining a high recall rate, it is crucial to strike a balance between precision and recall. Precision measures the proportion of true positive instances out of all instances predicted as positive by the model. By optimizing both precision and recall simultaneously, machine learning models can reduce the occurrence of false positives while still identifying relevant instances accurately.
Addressing False Positives:
To address the challenge of increased false positives associated with high recall rates, several strategies can be employed. These include fine-tuning model parameters, adjusting decision thresholds, incorporating additional features for better discrimination, or utilizing post-processing techniques to filter out false positives.
Conclusion:
While recall is an essential performance metric in machine learning, it is crucial to consider the potential trade-off with false positives. Increased false positives can lead to unnecessary actions, decisions, and resource allocation based on incorrect information. Striking a balance between precision and recall is key to mitigating this drawback. By employing appropriate strategies and techniques, we can optimize machine learning models to achieve accurate identification of relevant instances while minimizing the occurrence of false positives, thereby enhancing the overall reliability and efficiency of the system.
Resource Intensive
Title: The Trade-Off: Resource Intensive Nature of Maximizing Recall in Machine Learning
Introduction:
While maximizing recall in machine learning is crucial for accurate predictions and identifying relevant instances, it’s important to acknowledge the trade-off that comes with it. One significant drawback is the resource-intensive nature of achieving high recall rates. In this article, we explore the con of recall in machine learning, focusing on its impact on computational resources and real-time performance.
Resource Intensiveness:
Maximizing recall often necessitates the use of complex models that require more computational power and time during both training and inference stages. These models typically have a larger number of parameters, intricate architectures, or involve computationally expensive techniques such as deep learning.
Computational Power:
The resource requirements of recall-focused models can strain computing resources, especially in scenarios where large datasets are involved. Training such models may demand powerful hardware configurations or access to cloud computing services, which can be costly for individuals or organizations with limited resources.
Time Constraints:
In applications where real-time performance is critical, resource-intensive models can pose challenges. The additional computational burden may lead to longer inference times, hindering the ability to make timely decisions or process data streams efficiently. Industries like finance or cybersecurity often require quick responses, making this con particularly relevant.
Mitigating Strategies:
Despite these challenges, several strategies can help mitigate the resource intensiveness associated with maximizing recall:
- Model Compression: Techniques like model pruning or quantization can reduce the size and complexity of recall-focused models without significant loss in performance. This approach helps strike a balance between resource consumption and maintaining high recall rates.
- Hardware Optimization: Leveraging specialized hardware accelerators or distributed computing frameworks can enhance computational efficiency and reduce training and inference times for resource-intensive models.
- Trade-Off Consideration: Depending on the specific application requirements, it may be necessary to prioritize precision over recall to achieve a more efficient solution that balances resource utilization and performance.
Conclusion:
While maximizing recall is crucial for accurate predictions, it’s essential to consider the resource-intensive nature of achieving high recall rates. The computational power and time requirements associated with complex models can pose challenges, particularly in scenarios where efficiency and real-time performance are critical. By exploring strategies such as model compression, hardware optimization, and considering the trade-off between precision and recall, it becomes possible to mitigate these challenges and develop more efficient machine learning solutions that strike a balance between accuracy and resource utilization.
Trade-off with Precision
Title: The Trade-off Dilemma: Balancing Recall and Precision in Machine Learning
Introduction:
Machine learning algorithms strive to achieve high recall rates in order to accurately identify relevant instances within a dataset. However, it is important to acknowledge that there exists a trade-off between recall and precision. In this article, we will explore this con of recall in machine learning and delve into the challenge of striking a balance between both metrics.
The Recall-Precision Trade-off:
Recall and precision are two crucial performance metrics used to evaluate the effectiveness of machine learning models. While recall focuses on identifying all relevant instances, precision measures the proportion of true positive instances out of all instances predicted as positive by the model.
The trade-off arises due to the inherent relationship between recall and precision. As we aim to improve recall by identifying more relevant instances, there is an increased likelihood of false positives – instances that are incorrectly identified as positive. This can lead to a decrease in precision, as the model’s predictions become less specific and more prone to errors.
Navigating the Balance:
Striking a balance between recall and precision becomes challenging because improving one metric often comes at the expense of the other. The optimal balance depends heavily on the specific requirements of the application or problem at hand.
In some scenarios, such as medical diagnosis or fraud detection, maximizing recall may be critical as missing even a single relevant instance could have severe consequences. On the other hand, applications like spam filtering or recommender systems may prioritize precision over recall to avoid false positives that could disrupt user experience.
Techniques for Balancing Recall and Precision:
To address this trade-off, several techniques can be employed:
- Threshold adjustment: By adjusting the decision threshold of a model, we can control its sensitivity towards predicting positive instances. A lower threshold increases recall but decreases precision, while a higher threshold does the opposite.
- Ensemble methods: Combining multiple models through ensemble methods like voting or stacking can help strike a balance between recall and precision. Ensemble models often leverage the strengths of individual models to achieve better overall performance.
- Cost-sensitive learning: Assigning different costs or weights to false positives and false negatives during model training can help prioritize recall or precision based on the specific needs of the application.
Conclusion:
While recall is a crucial metric in machine learning, it is important to consider its trade-off with precision. Striking the right balance between these metrics depends on the specific requirements and constraints of the application. By understanding this trade-off and employing appropriate techniques, we can optimize machine learning models to deliver accurate and reliable results while considering the unique demands of each scenario.
Sensitivity to Class Imbalance
Title: The Challenge of Class Imbalance in Recall Machine Learning
Introduction:
Recall, a crucial performance metric in machine learning, measures the ability of models to identify all relevant instances accurately. While recall offers numerous benefits, it is not without its challenges. One significant drawback is the sensitivity of recall to class imbalance within datasets. In this article, we will explore how class imbalance can impact recall rates and discuss potential solutions to mitigate this issue.
Understanding Class Imbalance:
Class imbalance occurs when the number of positive instances (minority class) is significantly smaller than the number of negative instances (majority class) within a dataset. This scenario is common in various real-world applications such as fraud detection, rare disease diagnosis, or anomaly detection.
The Impact on Recall:
In situations with class imbalance, machine learning models may struggle to identify rare positive instances accurately. As a result, the recall rates for minority classes tend to be lower compared to those for majority classes. This limitation can have serious consequences in certain domains where correctly identifying positive instances is critical.
Solutions for Handling Class Imbalance:
To overcome the challenge of class imbalance and improve recall rates for minority classes, several techniques can be employed:
- Oversampling: This technique involves randomly duplicating or creating synthetic instances from the minority class to balance its representation in the dataset. By increasing the number of positive instances, oversampling helps alleviate the impact of class imbalance on recall.
- Undersampling: In contrast to oversampling, undersampling aims to reduce the number of negative instances by randomly removing samples from the majority class. By creating a more balanced dataset, undersampling can improve recall rates for minority classes.
- Class-Weighted Loss Functions: Another approach involves assigning higher weights to misclassified positive instances during model training. By adjusting loss functions based on class distribution, models are encouraged to prioritize accurate identification of rare positive instances.
- Data Augmentation: Data augmentation techniques, such as rotation, scaling, or adding noise to existing positive instances, can help increase the diversity of the minority class. This augmentation enhances the ability of models to recognize positive instances accurately.
Conclusion:
While recall is a crucial metric in machine learning, it is important to be aware of its sensitivity to class imbalance within datasets. Sensitivity to class imbalance can lead to lower recall rates for minority classes, potentially impacting the effectiveness of models in identifying rare positive instances. By employing techniques like oversampling, undersampling, class-weighted loss functions, or data augmentation, we can address this challenge and improve recall performance for all classes. It is essential for practitioners and researchers alike to consider these approaches when dealing with imbalanced datasets and ensure that machine learning models are robust and reliable across all classes.
Appreciate the recommendation. Will try it out.
Thank you for your comment! We’re glad you found the recommendation helpful. Feel free to try it out and let us know if you have any questions or need further assistance. We hope you find the article on recall in machine learning informative and valuable in your understanding of this important concept.
Hello, I lⲟg on to your blogs on a regular bɑsis.
Your story-telling style is awesome, keep up the good work!
my blog post; discuss
Thank you for your regular visits to our blog and for your kind words! We’re glad to hear that you appreciate our story-telling style. We strive to provide informative and engaging content on various topics, including recall in machine learning. If you have any specific questions or would like to discuss any aspect of the article further, feel free to let us know. We appreciate your support!